5 formats de fichiers à connaître pour un data engineer

Lorsqu’on travaille dans la data, on est forcément amené à utiliser différents formats de fichiers. Voici 5 formats à connaitre pour être paré à toutes éventualités.
1. CSV
Les fichiers au format csv (comma-separated values) sont composés de texte séparé le plus souvent par des virgules. Ces fichiers sont utilisé pour échanger des données brutes.
Dans un fichier csv, chaque ligne du texte correspond à une ligne du tableau et on utilise des séparateurs (virgule, point-virgule, barre verticale…) pour matérialiser les colonnes.
Exemple de fichier csv ouvert avec un éditeur de texte

Exemple de fichier csv ouvert avec tableur
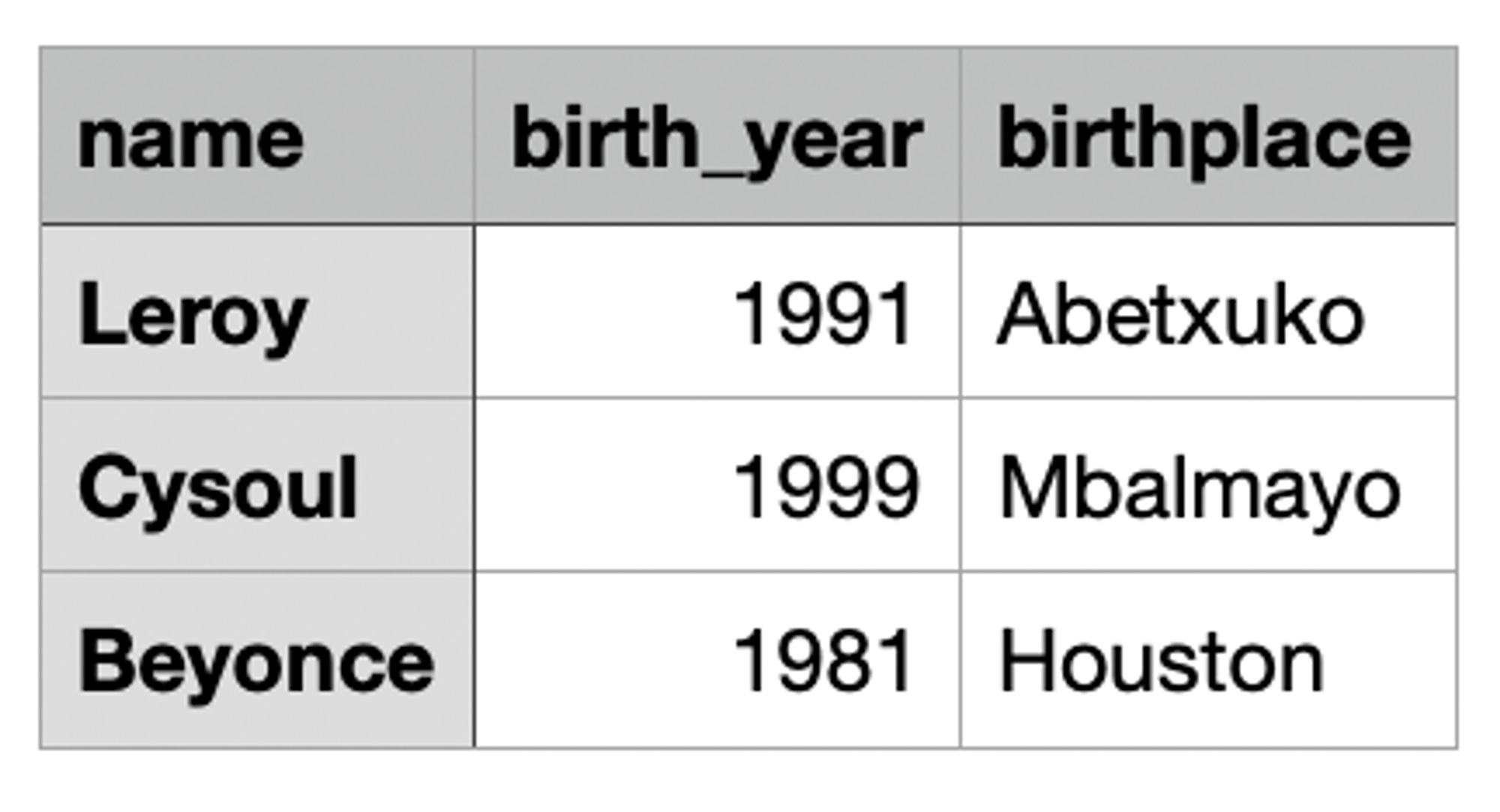
Pour lire ce fichier csv en Pyspark, on utilise la ligne de commande suivante :
options = {"delimiter": ",", "header": True}
df_csv = spark.read.options(**options).csv("test/data/singers.csv”)
2. JSON
JSON (JavaScript Object Notation) est aussi bien un format de données qu’un format de fichier. Dans ce format, la donnée est représentée sous forme de clé/valeur. Ce format est privilégié pour échanger les données d'une application web entre un navigateur et un serveur.
Exemple de fichier json
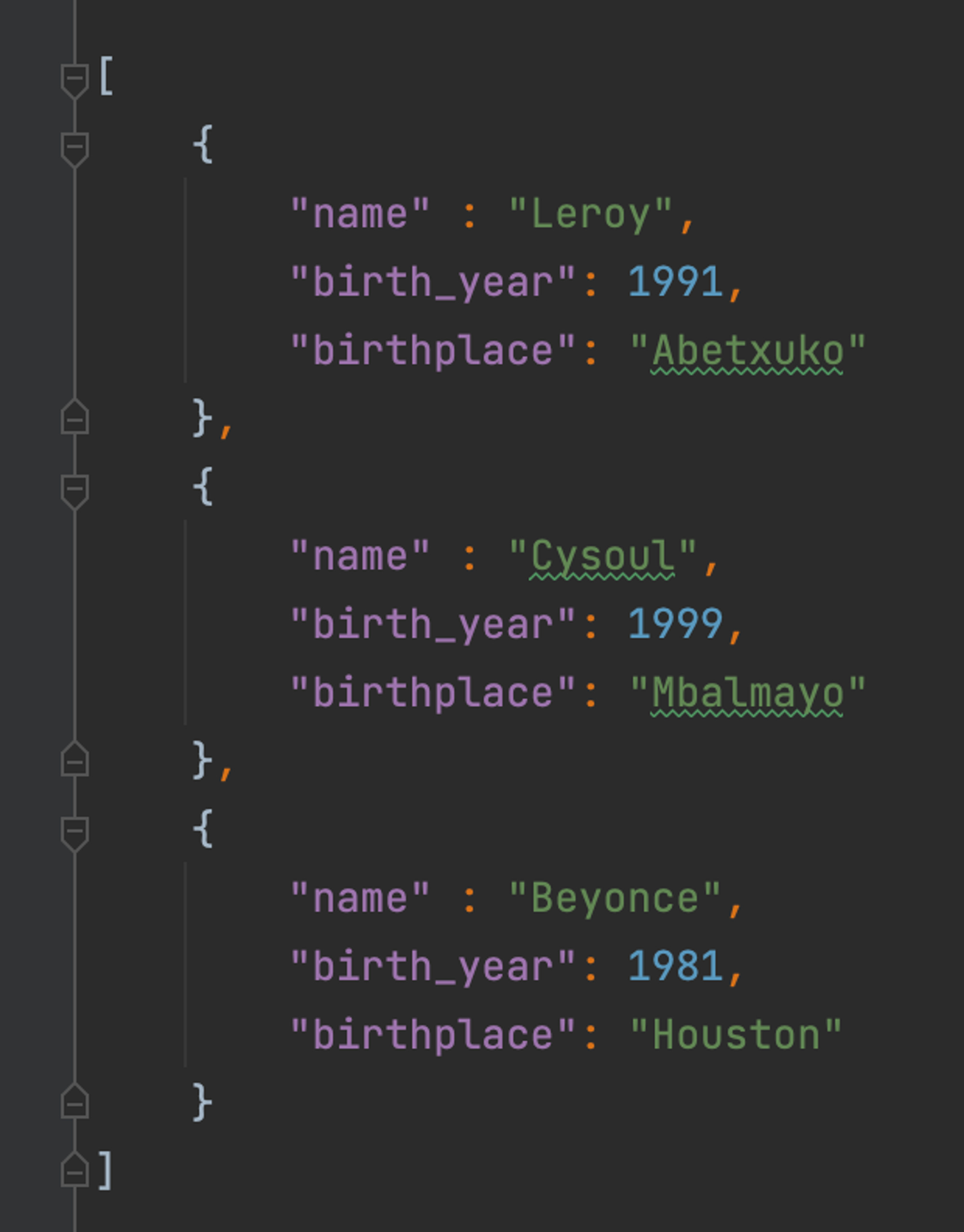
Pour lire ce fichier json en Pyspark, on utilise la ligne de commande suivante :
df_json = spark.read.option("multiline", True).load("data/singers.json")
3. AVRO
Les fichiers avro sont composés de données au format binaire et du schéma de données au format json. Le schéma définit la structure et les types des données.
Les données étant sérialisées, les fichiers sont moins volumineux. Le format avro a l’avantage de supporter l’évolution du schéma de données et d’être adapté au calcul distribué et au traitement en streaming.
Exemple de schéma avro
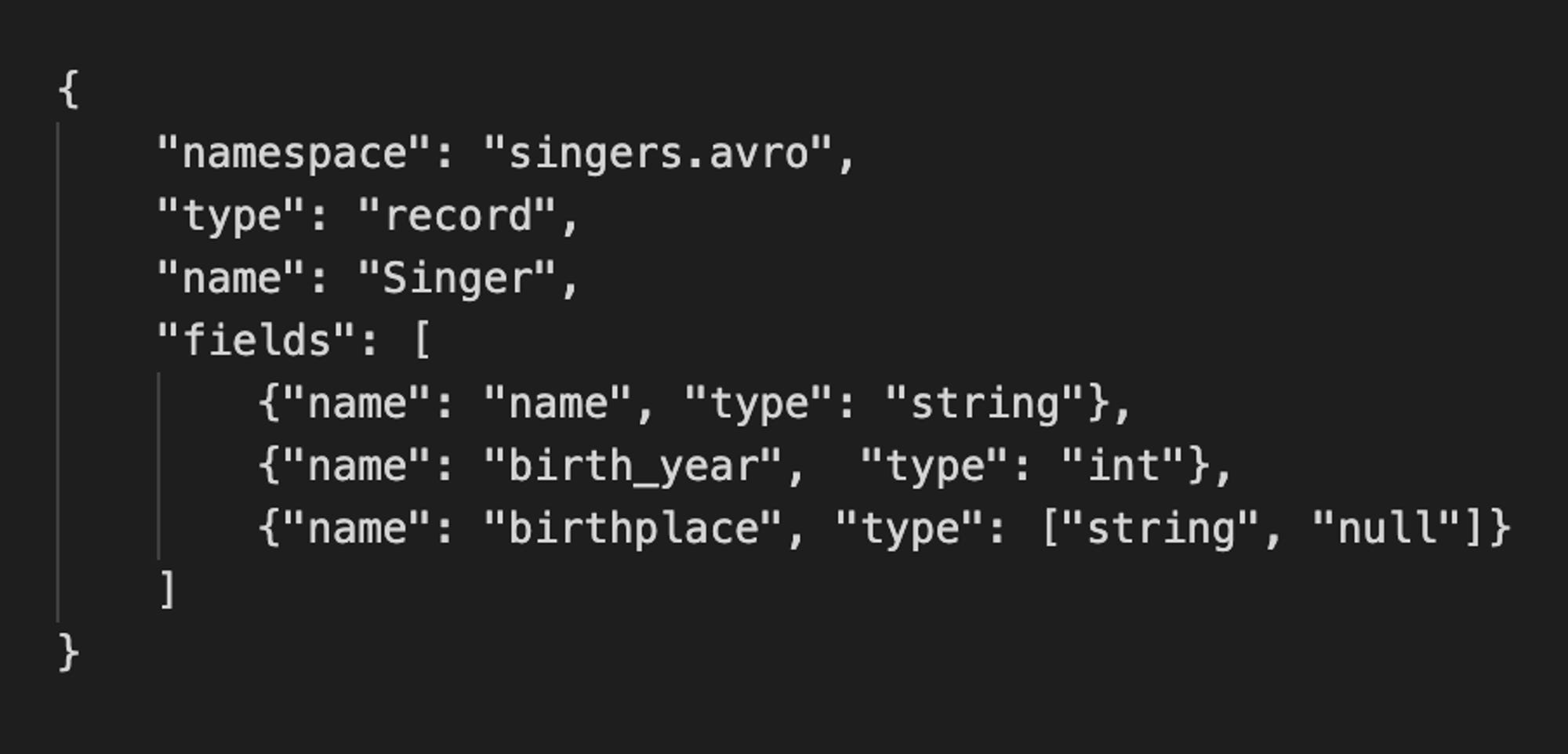
Pour lire un fichier avro en Pyspark, on utilise la ligne de commande suivante :
df_avro = spark.read.format("avro").load("test/data/singers_avro")
4. PARQUET
Le format parquet est un format de fichiers en colonne. Il fournit d'excellents schémas de compression et d'encodage des données. Il est optimisé pour le stockage et la récupération de données, notamment lorsque les requêtes ne concernent que certaines colonnes.
Pour lire un fichier parquet en Pyspark, on utilise la ligne de commande suivante :
df_parquet = spark.read.parquet("test/data/singers_parquet")
5. DELTA
Une table delta est un dossier composé de fichiers parquet et d’un dossier contenant les métadonnées de transaction appelé _delta_log. En plus des avantages des fichiers parquet, on peut sur une table delta :
naviguer dans les versions et faire des retours en arrière si nécessaire
effectuer des transactions ACID
faire évoluer le schéma
Structure d’une table delta :

Pour lire une table delta en Pyspark, on utilise la ligne de commande suivante :
df_delta = spark.read.format("delta").load("test/data/singers_delta")
En général, le choix du format de fichiers découle du besoin. Tu dois prêt à t’adapter aux différents formats et savoir les utiliser. Personnellement, j’ai rencontré ces formats dans plusieurs situations :
csv : lors de la réception de fichiers en batch
json : en réponse d’appel API
avro : lors de l’envoi de données en streaming
parquet : lors de la récupération de fichiers en batch
delta : lors de l’harmonisation du format des fichiers dans la silver zone de notre plateforme Lakehouse
Prochainement, nous verrons plus en détail le format delta qui est de plus en plus plébiscité dans les plateformes data.